Published originally on Medium (opens new window)
Recently I did a project where I used Cloudflare workers. In this article, I’ll give an introduction to how they work and some use cases.
This article was written out of my own experience, I did not get paid nor did I get compensated by Cloudflare for writing this article.
# What is Cloudflare?
Cloudflare is a company that sells different services like DNS, CDN, DDoS protection and many other services, one of their more recent services are called “Cloudflare workers”.
To be able to benefit from Cloudflare workers, you will need to be using their DNS service as it’s complementary to their DNS service. When using also their CDN, you’ll be able to maximize the value out of Cloudflare workers.
# What is a Cloudflare worker?
A Cloudflare worker is a serverless function, written in JavaScript, that runs on the edge. That’s the short, sexy explanation.
- Serverless means you write code which does not require you to scaffold the server and host that the code will run in. You just write your code and deploy it, the one that hosts (in this case Cloudflare) the serverless code takes care of hosting, server bootstrapping, infrastructure and scaling. A known comparable service is Lambda from AWS.
- When we talk about the edge, we mean the closest geographically located data center to the visitor of your site which tries to access your site via the Cloudflare DNS. Cloudflare has its own data centers all over the world to provide its services like DNS and CDN so it can serve visitors with a minimum of delay by spreading these data centers strategically all over the world.
When using Cloudflare’s DNS, it is important to know that requests go through their data centers (when you choose so, but mandatory to use Cloudflare Workers).
When using Cloudflare workers, a request will follow the following path:
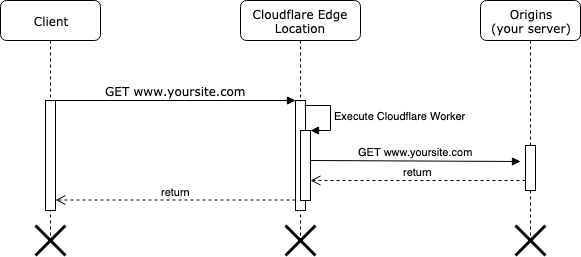
Every request will be intercepted by the closest Cloudflare Edge location and this will trigger your serverless function to execute. In this function, you have total control if you forward the request to your origins server or execute your own logic. You can even fetch resources from different servers and then aggregate these results in one response for the client, more examples later.
Note that this function executes to the closest data center near to the client. When you deploy a Cloudflare worker, the code will be deployed to all Cloudflare’s edge locations.
# How does the code look like?
The Cloudflare worker code in the simplest form looks like this:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
});
async function handleRequest(request) {
// Any logic you want
return fetch(request);
}
2
3
4
5
6
7
8
Typically to JavaScript, we start off with creating an event listener to the fetch event on line 1. The fetch event is equivalent to the event of an incoming request to the Cloudflare edge location.
For code readability, we create a separate function handleRequest() where we will put our custom logic. Notice we have a similar API and coding experience as to a Web Worker in a browser where we basically also want to intercept requests so we can do caching browser side.
# The Runtime
The Cloudflare worker code runs in a barebone V8 runtime, at the time of writing they are using v8 v7.4, and they upgrade it regularly. Meaning you can use the latest features like async/await and the latest V8 improvements like the Orinoco (opens new window) garbage collector.
Along with the runtime comes the cache API (opens new window) and the fetch API (opens new window) that we find in modern browsers. So it’s easy to natively do any HTTP requests. Notice that the request object passed to HandleRequest() is an instance of the Request (opens new window) type from the Fetch API. Almost the entire fetch and Cache APIs are the same as in the MDN docs, but there are a few differences (opens new window).
# What About Node modules?
We run in a barebone V8 environment just like in a browser, so node modules are not natively supported. Although you can use any node module and use Webpack to concatenate all your dependencies and different source files into a single file that you can deploy to Cloudflare. When running webpack you need to specify as target webworker.
The downside when using webpack is that you get one uglified concatenated file that puts all code on a single line of text. Meaning that your stack traces will be obfuscated and not readable.
# Handling Errors
When a Cloudflare worker executes, you don’t have access to the stdout of the worker. You only have this in the “testing” interface that Cloudflare provides but when running on production, you need to append code to log your errors to a remote server or service. As said before, make sure to have proper error descriptions when you are using webpack to concatenate all your code within one file. Because the stack trace won’t be readable in that case.
# Caching
This only works if you also use the CDN service of Cloudflare, then you can use the Cache API which maps to the local cache of the local edge location where the worker is executing. This is an incredibly useful feature when you want to implement custom logic regarding the caching of assets.
# Route Matching
For your convenience, when you enable a Cloudflare worker, you can configure multiple route matching URL’s so you don’t need to implement this logic within your Cloudflare worker’s code.
# Use Cases
We have this distributed deployed, serverless function that runs on the Cloudflare edge locations. So why or when would we want to use this? Cloudflare does provide a list of recipes (opens new window), the possibilities are infinite.
The project I worked on was to optimize the caching strategy for a specific web service. The combination of using Cloudflare Workers, their DNS, and CDN service, I was able to optimize the caching strategy by implementing custom logic saving a lot of money on the cloud vendor bill from having a 90% decrease in data-out bandwidth from given cloud service.
In another project, I used the web worker for assigning visitors to A/B variance groups and used two different origins to gather cookies and merge them on the response.
The beauty is that you basically can program your own custom proxy logic, executed on the edge, meaning, close to the client for low response times. You can write any logic without any cold start issues. Execution time and startup speeds are extremely low so the impact is low putting a Cloudflare worker between your requests.
# Challenges
A few challenges to keep in mind.
*Logging needs to be done to an external server, so you need to make an HTTP request to log entries. If that request fails, you will have a silent fail without any information to go on. *You can only deploy one Cloudflare worker per top level domain. So if you have your staging environment hosted as a subdomain (e.g. staging.yourbrand.com) you can’t deploy the worker for staging purposes. You will need to have another top level domain, using Cloudflare DNS where you can deploy the staging version of your Cloudflare worker.